BY
=
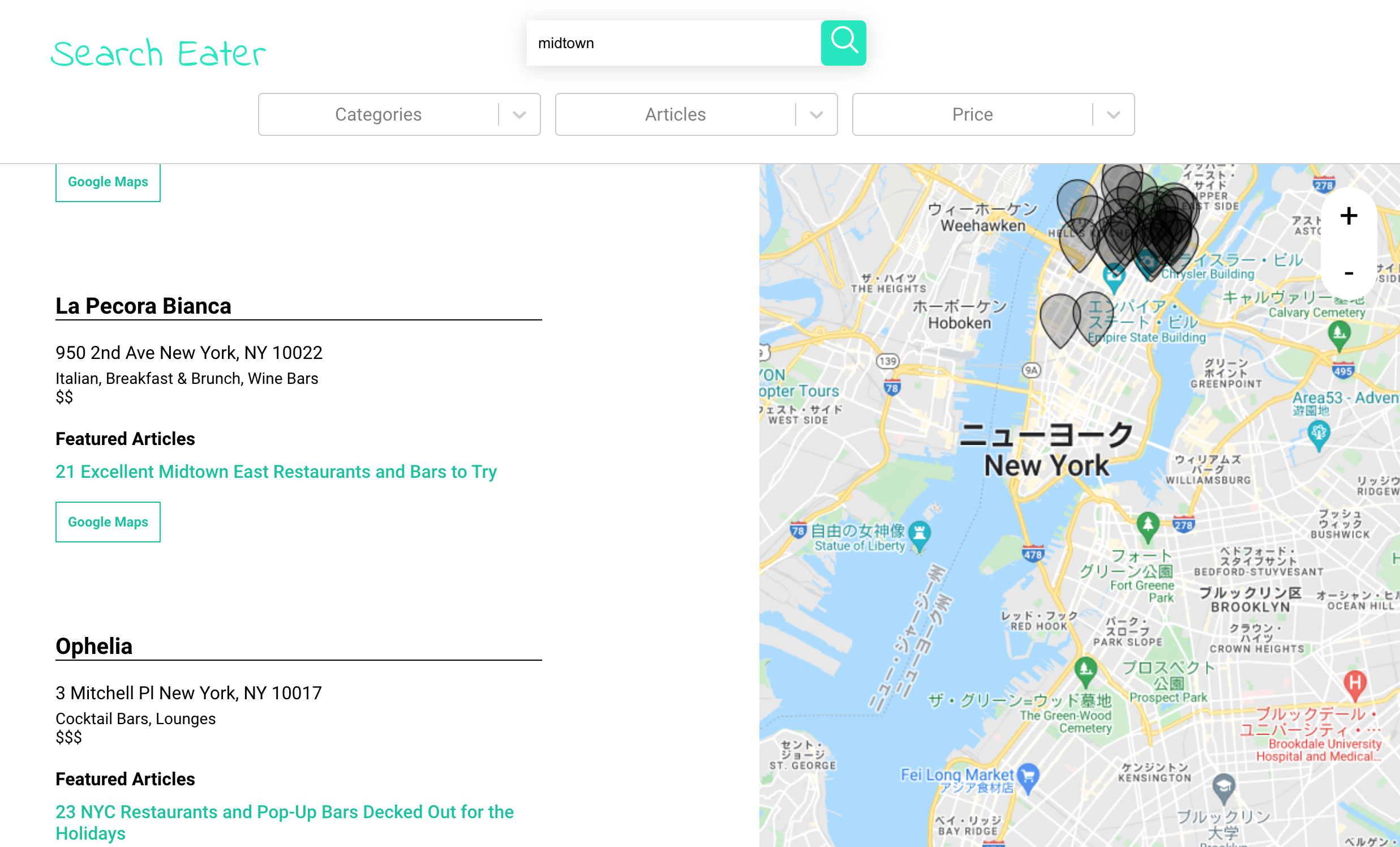
Eater NY is a website that writes about restaurants all over NY. They create maps that feature restaurants that share a theme. Example articles include: Best New Cocktail Bars, 11 Places to Dine Out on Monday
Eater NY's search engine is built to search for articles, not restaurants. As a user, using their search sometimes feels a little restrictive because it is difficult to quickly browse restaurants using their search engine. A search engine similar to Yelp or Google Maps would give the user more flexibility and freedom when searching.
However, one merit of using articles is that restaurants are grouped according to themes. For example, if I just wanted to find breakfast burritos, I can look through this article.
To combine the best of both worlds - the food themes from grouping restaurants by articles and a restaurant-focused search - I decided to build Search Eater.
Building both the front-end and back-end of a search engine as a side project was an extremely educational experience. In addition, by building something that I would actually use, the experience was also both rewarding and fun.
Mongo DB + Atlas Search + Redis
Semantic Search using deep learning with SBert + FAISS
Deployed using a Docker image to bypass the 500MB slug limit from Heroku
Scraper: BeautifulSoup + Heroku Scheduler to run script daily and fetch metadata using the Yelp API
With great flexibility comes great responsibility. With MongoDB, the developer has the power to design a schema that does not need to conform tonormalization rules. In fact, designing a schema that works for your application first and foremost is the general rule of thumb when it comes to designing a MongoDB schema.
Fortunately, the flexibility and speed at which the developer can iterate with MongoDB makes it easy to experiment with various schema choices.
While implementing a search engine that uses text-matching is quite straightforward using Atlas Search, learning how to build a semantic search engine was a little more challenging.
Learning about how semantic search works from a theoretical level,reading articles on how others have implemented it, and finally building it was time consuming but rewarding.
As more models and features are added, data integrity (i.e. if I add a new restaurant from an article, will all data models be updated accurately?) and data security becomes much more important. Using an existing back-end framework can make these checks much easier.
Currently, this project only uses Eater from NYC. However, Eater has articles from cities all over the world. In addition, there are many sites that write about restaurants (e.g. Infatuation, Time Out). Aggregating all of these websites would make this search engine much more powerful.
One feature that can be added quickly is a restaurant page that shows all of the articles that a restaurant was featured in. By doing so, if a user is interested in seeing everything that was written about a restaurant, they can do so in a single view and also click on links that take them to the article.